
こんにちは、IT統制セクション データマネジメントグループの宮澤です。
2009年にぐるなびに入社し、データベース管理者(DBA)としてキャリアを重ねてきました。2016年からは、データ管理者(DA)のチームを発足し、関係各部署と協力し、全社的なデータマネジメントの企画・検討と推進を行っております。
ぐるなびにおけるデータマネジメントの取り組みについては「メタデータ管理のすすめ」の中で公開されていますので、ご興味のある方は、合わせてお読み頂ければと思います。
私の所属するIT統制セクションは「データ利活用の促進」もミッションの一つに掲げており、社内データはもちろん、昨今話題になっているオープンデータの社内利用や連携なども検討しておりました。
そんな折、日頃からお世話になっている日本データマネジメント・コンソーシアム(JDMC)の「エンジニアの会」において、あるイベントの出場者を募集していました。

内容は「Oracle Cloud の Autonomous Database を使い、オープンデータを楽しく分析し、ビジネス賞、アイデア賞を競い合う」というものです。
※詳細はイベントページをご参照下さい。
先に述べたように、我々の業務領域は全社的なデータマネジメント推進であり、分析業務に深く携わっている訳ではありません。しかし、オープンデータの調査や、分析を学習する良い機会と捉え、チームで参加を決意しました。
ただし、オープンデータ・分析・Oracle Cloudについての知見が乏しい状態に加え、選手権まで約1ヶ月。日本オラクル様開催の「Oracle Cloud ハンズオン」から約10営業日とタイトな日程であり、不安もありました。
※選手権までのマイルストーンと当初のタスクスケジュール

今回はそんな中でもOracle Cloudをつかった機械学習で、「飲食店のフードロス」という、ぐるなびと親和性の高い社会課題に取り組んだ内容をご紹介。
課題設定もさることながら、はじめて触ったOracle Cloudはとても操作性に優れ、普段分析業務を行っていない私でもとっつきやすいものでした。 分析や機械学習、クラウド、オープンデータに興味がある方、又は、これから取り組まなくてはならないという方はぜひ参考にしてみてください。
Oracle Cloud の機械学習
イベントまで3週間弱に迫った2/8(金)、日本オラクル本社にてハンズオンに参加。参加にあたり、Oracle Cloudの無償アカウント(30日間)の開設と、目ぼしいオープンデータの調査を終わらせておきます。
後は実際にOracle Cloudに触れて、やれることやれないことを判断し、具体的な発表内容をふくらませる計画です。
半日をかけたハンズオンの主な内容はざっくりとこちら。
- Autonomous Data Warehouse Cloud(ADWC)、Oracle Analytics Cloud(OAC)の構築
- ローカルPCからADWCにデータ投入
- OACからADWCへ接続
- OACでアドホック分析、可視化
これで一通りOracle Cloudに触れられる状態になりました。

上記のハンズオンに加え、後日、機械学習の資料も展開していただき自習しました。
OACに用意されている主な機械学習モデルは、以下の通り。
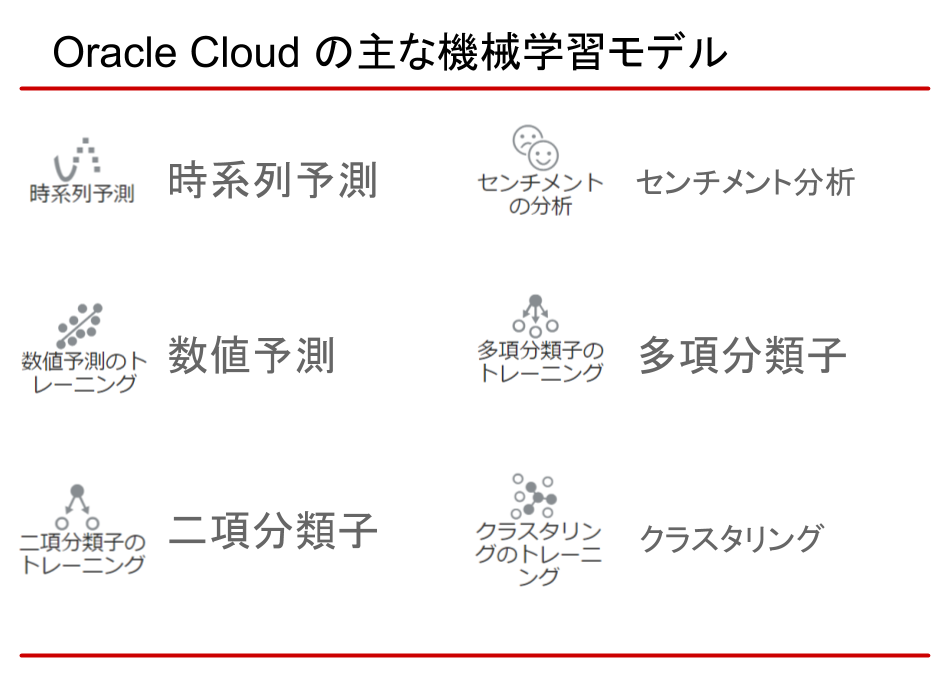
実際にモデルを生成・適用する場合は、OACの「データフロー」という機能を使います。「データフロー」は、機械学習以外でも、データのマージや加工などができます。
参考までに、機械学習モデルを生成・適用する画面を紹介します。
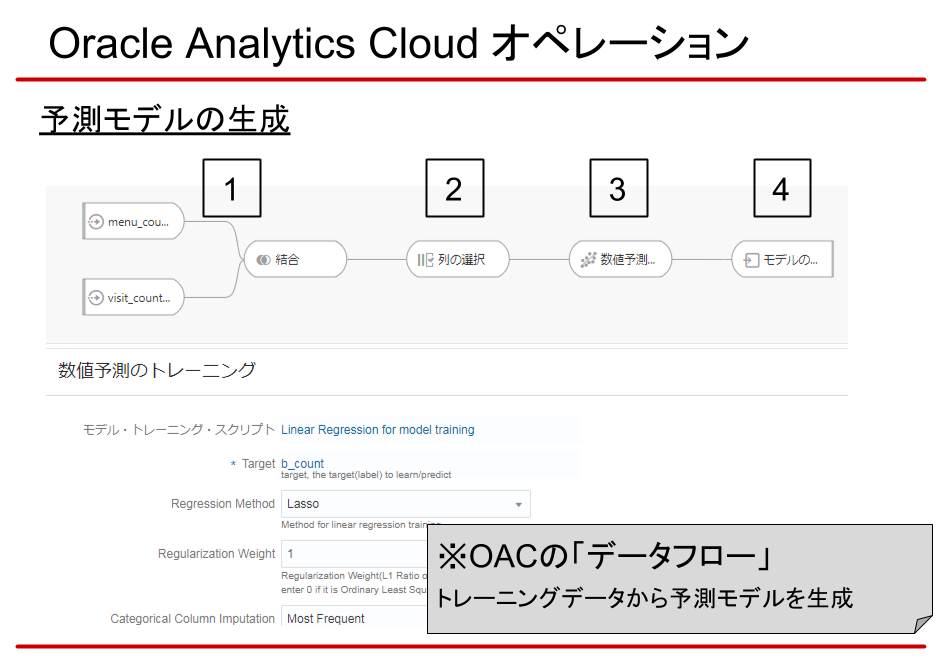
- 入力データの指定
ここでは、モデル生成に必要なトレーニングデータを使います。
複数ある場合は画面のように結合もできます。 - 列の選択
- 機械学習モデルの選択
今回は、例として数値予測を選択しています。
予測対象の列や、モデルで使用するメソッドやパラメータなどを調整します。
※先述のモデルに加え、RやPythonのカスタムスクリプトの適用も可能なようです(動作は未確認) - モデルの生成
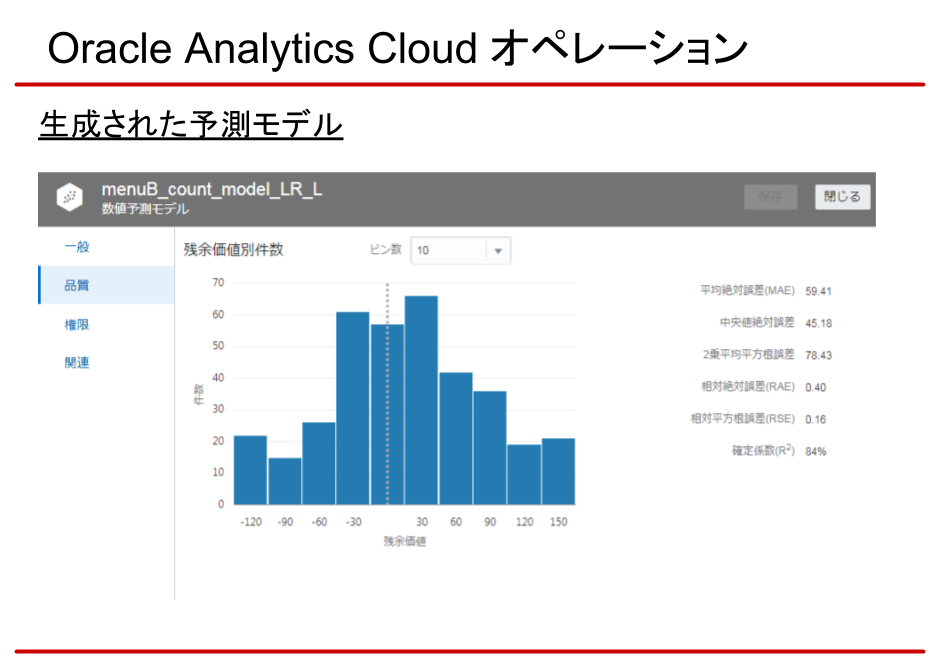
生成されたモデルは下記のように確認できます。
ただし、生成のロジックはブラックボックス。意図しない結果になることもあります。その場合は、トレーニングデータの準備や、モデルの生成で試行錯誤することになります。
最後に、生成したモデルにテストデータを適用し、予測データを出力します。
ここでも「データフロー」を使います。
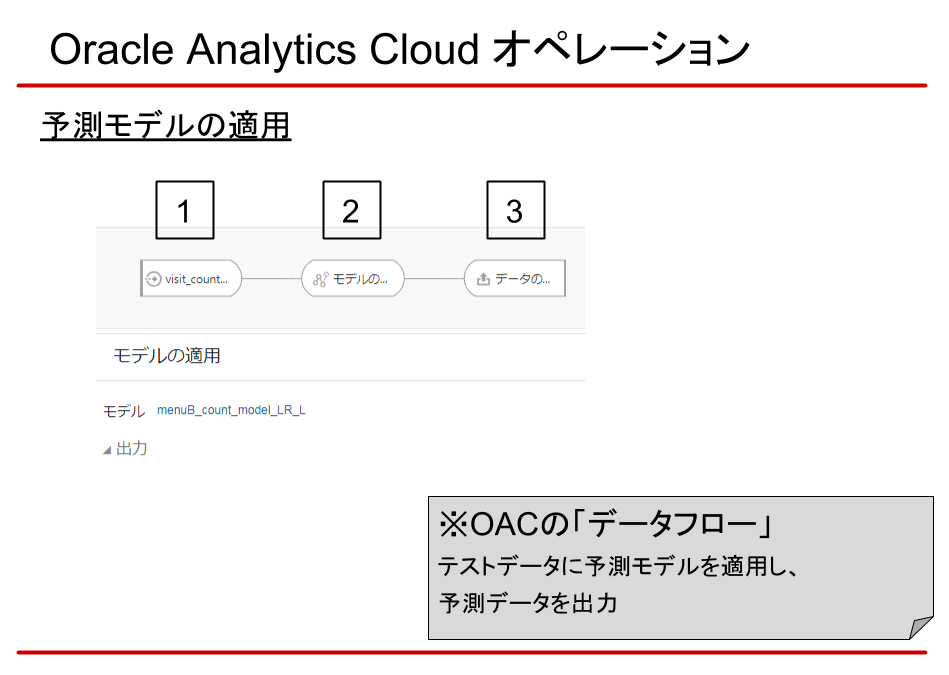
- 入力データの指定
ここでは、予測させたいテストデータを指定します。 - 生成した予測モデルの適用
- 予測データの保存
以上が、機械学習のオペレーション例です。
Oracle Cloudは他のCloudサービスと同じように、サービスの利用や、データベースの構築・管理がボタン一つで簡単に行えます。
特にOracle RAC は、他のRDBMSに比べ構築・運用が大変ですので、ORACLEデータベースに依存度が高いシステムであれば、利用するメリットは大きいと感じます。
そして、Oracleの管理をクラウドに任せる事で、DBAの負担が大幅に軽減される点には強く惹かれました。
オープンデータの分析を進め、スモールスタートに行き着く

1. オープンデータの壁
フォーマット
公開元(各省庁や研究所など)によってフォーマットが異なるため、データ投入の前処理として、人による目視確認とパースが必要になります。無作為に多種多様なオープンデータを扱うとなると、作業コストが膨大になりました。集計単位
同じように集計単位(年/月/日など)もバラバラなため、相関関係を抽出する場合、最も粗いデータに粒度を揃える必要がでてきます。
例えば、気象情報は日次で揃っていても、人口統計や感染症情報が年次のため、結局、年次単位にサマリーしないと比較できません。ここでもデータを整備する作業が発生します。言語
世界各国のオープンデータにも目を向けましたが、英語ならまだ読めても、スペイン語やポルトガル語、アラビア語などになるともうお手上げです。
オープンデータであって、オープンデータに非ず・・・ これらを翻訳し取りまとめるサイトがあれば、ビジネスになると感じました。
(後日談:実際に運営されているようです)
2. 大量データの壁
単純にロード時間が長くなるうえ、接続切れなどの不具合が発生する確率も上がります。
また、大量になればなるほど、ロード時に発覚するデータの例外パターンも増え、事前処理からやり直すなどの手間も増えました。
さらに、分析においても、OACのレスポンスが遅くなります。
このままでは、目的のデータ分析以外で時間を取られてしまい、発表どころではありません。仕方なく、スモールスタート(必要最低限のデータ)で進める方向に転換しました。
そして、紆余曲折を経て、最終的に辿り着いたテーマが、こちらです。
『分析の業務経験ゼロでもできる!「Oracle Cloud」の機械学習で、飲食店の廃棄ロスに挑む』
テーマを絞り機械学習に一本化することで、多種多様なオープンデータ、大量データの呪縛から逃れられると考えたのです。
「食品ロス」の実態
本来食べられるはずの食料が、賞味期限切れや食べ残しなどを理由に廃棄されることを「食品ロス」といいます。
世界では、食料の1/3にあたる13億トンが、毎年、廃棄されているといいます。(出典:国際連合食料農業機関「世界の食料ロスと食料廃棄」報告書(2011年))
日本に目を向けると、年間およそ632万トン。毎日毎日、国民1人がお茶碗一杯分、食料を捨てていることになります。そのうち、飲食業界で廃棄される食料は年間およそ120万トン。全体の約5分の1に相当すると言われています。(※参考記事:政府広報オンライン, 飲食店.COM)
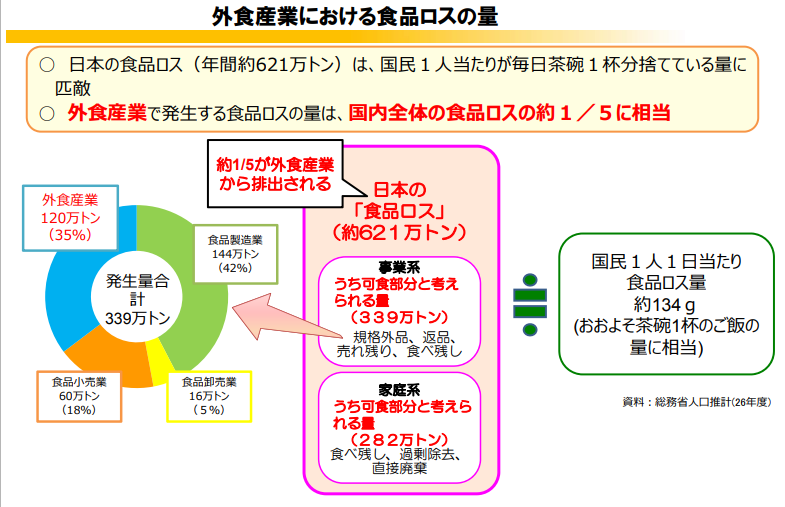
「食品ロス」に対する対策
海外では、食品ロスの改善策が進んでいる国が多いようです。
アメリカ:持ち帰りドギーバッグの浸透
フランス:食品廃棄の量に対して罰金徴収
デンマーク:賞味期限切れ食品の専門スーパー
スペイン:余剰食品をシェアする連帯冷蔵庫の設置
残念ながら、日本では衛生面の問題もあり、持ち帰りなどの施策はなかなか浸透していないというのが現状です。それでも最近は、食べ残しをなくす運動や、フードシェアサービスのアプリの出現などにより、少しずつ意識が高まってきています。
※参考記事
そんな中、我々が今回トライしたのは、極力、余剰食品を出さないための根本的な施策。それは、機械学習により正確な来客数と注文数を予測し、適切な仕入れを実現することでした。
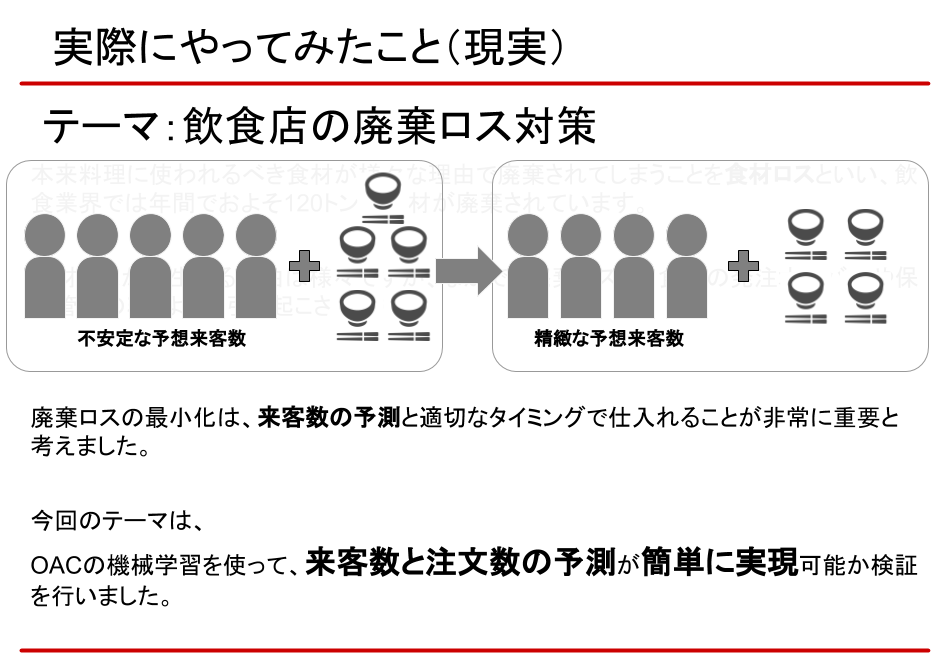
データセットと予測シナリオ
機械学習のデータセットとシナリオは、kaggleを参考にしました。
実際に用意したデータセットはこちら。
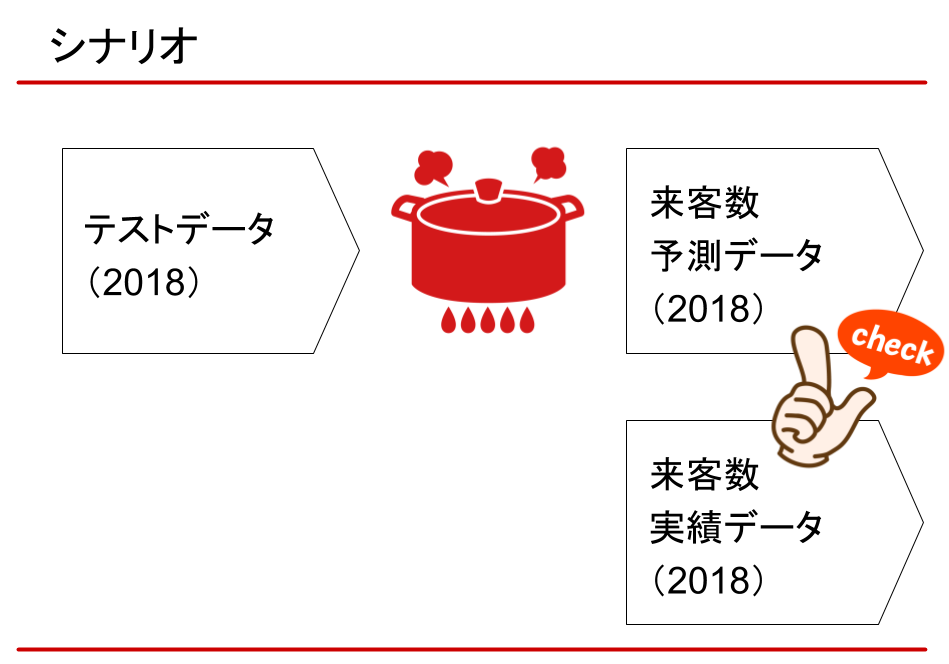
シナリオにおいては、まず、トレーニングデータとして2017年の実績データを用意。
それをインプットし、来店数と注文数を予測するモデルを生成します。
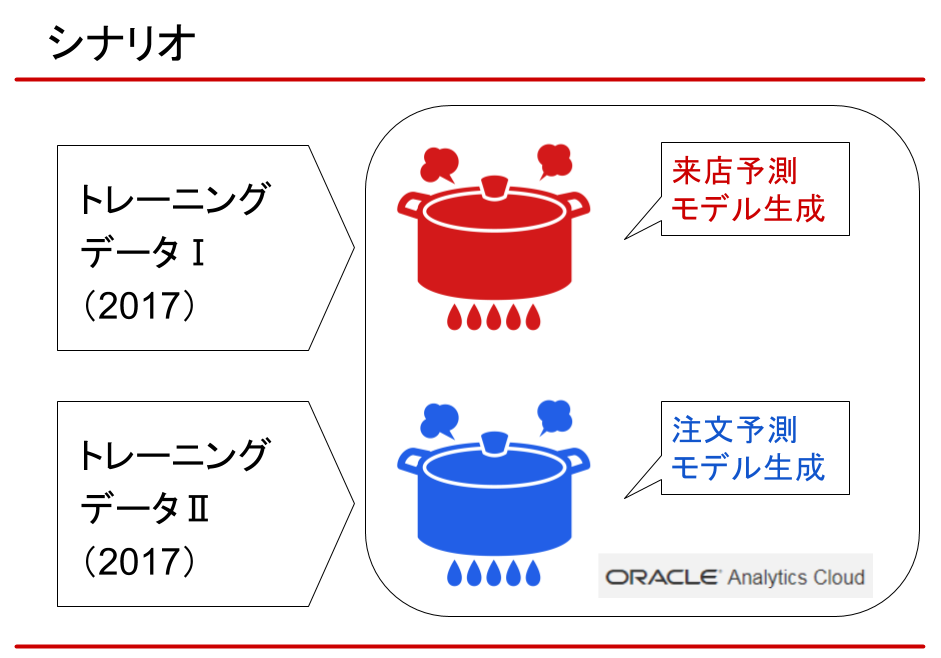
次に、2018年のテストデータを予測モデルに適用し、予測データを出力します。
そして、2018年の来店実績、注文実績と比較し、モデルの妥当性を評価しました。
予測モデルの生成、及び、予測データの出力にかかる時間は、それぞれ数十秒程度でした。この位であれば、気軽にトライ&エラーを繰り返せます。
当初は、どんな結果になるか見当も付かなかったため、入力データをシンプルにすることを心掛けました。例えば、比較的、傾向がはっきりしていて予測しやすそうな模擬店舗とメニューのパターンを用意するなどです。
加えて、イベント情報は、定量的な数値に置き換えて、OACが判断しやすいように加工しました。
そして、最終的に出来上がったプレゼン資料はこちらです。
発表当日
いよいよ選手権当日、はじめて社外イベントで登壇します。
会場で振舞われたお酒の効用も否めませんが、不思議と緊張はありませんでした。資料やリハーサルなどの準備が入念にできた事、ストーリーを極力シンプルにした事が大きかったのではと思います。
OACを使うと、専門的な知識がなくても機械学習を利用できますので「来客数と注文数の予測によってフードロスを解決する」という、本質的に解決すべき課題に注力できたのです。本業ではない我々のような人間が、ここまで手軽に分析を扱えるようになったことは驚きでした。
実際の発表の様子は、いくつか記事になっていますのでそちらをご覧いただければと思います。
今後の展望
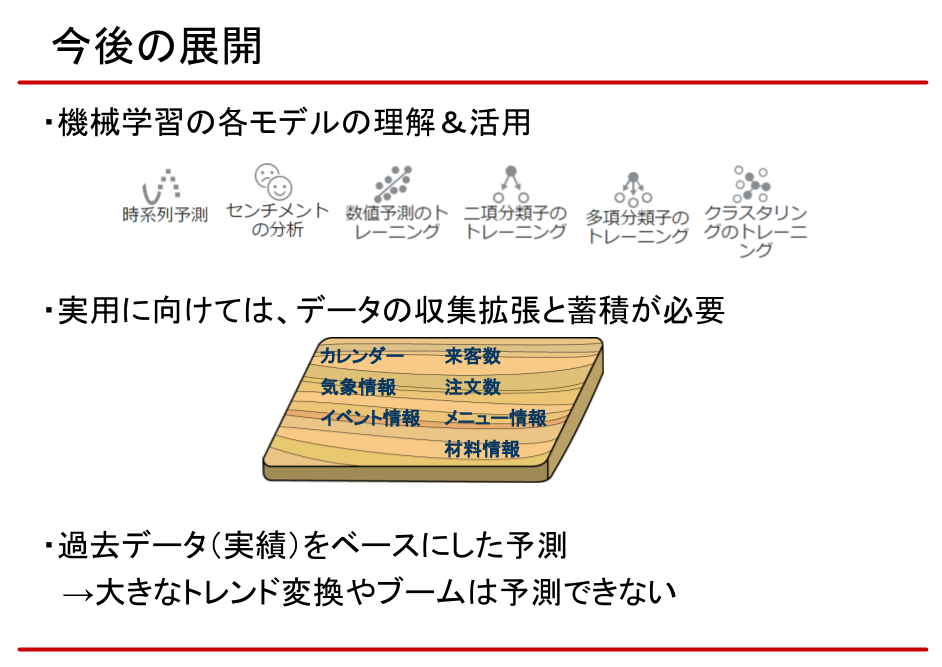
今回の予測モデルですが、実用化に向けてはまだまだ改善の余地があります。 まず、教師データの不足です。様々な飲食店の実績データの蓄積を進めることで、精度や応用範囲が広がります。
例えば、同じエリア、同じジャンルの実績情報が集まれば、新規出店時の来客予測や、メニューの検討にも応用できそうです。
また、あくまで過去の実績をベースにした予測に過ぎず、大きなトレンド変換やブームは予測できません。そのため、定期的に予測モデルの微調整は必要になりそうです。
一方で、トレンドやブームを仕掛ける側に回ることができれば、大きな強み、優位性を得られます。弊社では、トレンドメニューの分析などを「ぐるなびデータライブラリ」で提供しておりますが、メニュー開発などの観点で、AIや機械学習を活用するのも面白い取り組みではないでしょうか。
最後に
今回は、イベント参加を通して、貴重な体験と多くの学びを得られました。
特に「与えられた環境、条件の中で、取捨選択しベストを尽くしたこと」「余裕を持ったスケジュール管理を心掛けたこと」は、今後の糧になりそうです。
Oracle Cloudに用意されたツールを使うだけで、これだけの結果を得られた事は驚きでした。一方で、専門知識がないことによる限界も強く感じています。 強力なツールをさらに高いレベルで使いこなすには、少なくともそこに用意されているモデル、メソッド、パラメータを理解し、ベストの判断をするだけのスキルは必要です。
そういう意味では、まだまだ、学ぶべきことは沢山ありそうです。
最後に、イベント関係者の皆様、及び、出場を快諾してくれた上長と、一緒に試行錯誤し頑張ってくれたチームメンバーに感謝します。有難うございました。

お知らせ
「焼きおにぎり」は英語で? Alexaで 料理メニューのクイズにチャレンジしてみませんか。
※2019/04/16 18:02 「メタデータ管理のすすめ」の記事公開に伴い、一部文言修正と記事リンクの追加を行いました