
こんにちは。ソフトウェアエンジニアの吉村と申します。 会社ではUMAME!の開発を行っています。バックエンドからキャリアを始めていますが、モバイル、ウェブフロントエンド、クラウドインフラ、AIエージェントなど、なんでも設計/実装します。アドベントカレンダーの10日目はAI時代におけるソフトウェアアーキテクチャとの向き合い方について思考実験的な話をさせていただければと思います。どうかお手柔らかにお願いします。
導入
最初に、ひとつだけお断りを入れておきます。 「Domain-Driven Design (2003)」、「The Clean Architecture (2012)」、「Atomic Design (2013)」。これら洗練されたソフトウェアアーキテクチャ論は、長らく私たち開発者の指針となってきました。 さらにその源流である「Structured Design (1979)」や「A Pattern Language (1977)」まで遡れば、私たちの知恵は半世紀近く積み上げられてきたことになります。
昨今話題の「機能単位 (Package by Feature) か、レイヤー単位 (Package by Layer) か」という議論も、この界隈の話題の断片的な1つなのかなと思います。それは結局のところ、肥大化するシステムをいかにして「人間の認知限界」の中に収めるかという論争ではないでしょうか。
本記事ではその議論のテーブルにつきません。なぜなら、前提が異なるからです。 Cursor 2.0、Claude Opus 4.5、そして Google Antigravity...。 2025年の後半に立て続けに登場したこれらのAI Coding Agentの進歩には目まぐるしいものを感じます。 近い将来──それは来月かもしれませんし、10年後かもしれませんが──これまでの「人間が書き、人間が直す」という前提が完全に崩れ去ったとき、私たちが信じてきたアーキテクチャの常識はどう書き換わるのか。 本記事は、そんな大きな転換点の只中にいる今、少し先の未来を見据えて思考を巡らせてみた記録です。
つまり、これは従来のソフトウェアアーキテクチャ論ではありません。議論の前提が異なります。その点を踏まえて突拍子もないことが書いてある読み物という感覚で捉えていただければ幸いです。
警告:本記事で紹介する手法は、リスクを完全にコントロールできる環境下でのみ成立するいわば「劇薬」です。安易に採用すると、データの不整合や保守不能なコードベースを生み出す危険性があります。
AIという洪水
AI、特にAI Coding Agentの台頭がもたらした最大の変化は、まるで洪水のように溢れ出る「圧倒的な実装の量とスピード」です。
これまで私たちは、限られたリソース(人間の時間と認知能力)を節約するために、コードを共通化し、抽象化することに心血を注いできました。そうしなければ、複雑なシステムを管理しきれなかったからです。 しかし、AIはその制約を軽々と飛び越えていきます。
この奔流を前にして、既成観念というダムでAIという洪水をせき止めようとするのは得策ではありません。むしろ、この流れを最大限に活用するために、私たちは長年信じてきた「美学」を一度手放す必要があります。
共通化の美学からの脱却
その「手放すべき美学」の代表例が、私たちが長年信奉してきた共通化 (DRY原則)です。 AI Coding Agentを最大限に活用する鍵は、意外に思われるかもしれませんが「ボイラープレートやコードの重複を恐れない」ことにあると私は考えます。
「A little copying is better than a little dependency.」by Rob Pike
私はGo言語を勉強した時に彼の言葉にとても共感したことを覚えています。 私たちはこれまで、「コード量の削減」こそが正義であると信じ、共通化にこだわってきました。もちろん、共通化には保守性や変更容易性といった重要な側面もあります。しかし、そのトレードオフを軽視した結果、「早すぎるDRY (Don't Repeat Yourself)」に苦しめられた経験は誰にでもあるはずです。 たった一箇所の共通処理を修正するために、影響範囲調査に数時間を費やし、結局修正を諦めてif文で分岐させた経験が、あなたにもあるのではないでしょうか。
AI Coding Agentの登場により、状況は一変しました。圧倒的な生成スピードと、実装コストの劇的な低下。これらを前にして、「コード量を減らすこと」の経済的価値は相対的に低下しています。
ここで私はひとつの仮説を立てます。 AI Coding Agentの台頭により、もはや「A little(少し)」という制約すら不要になりつつあるのではないか、と。 CopyingかDependencyか。その選択に何らかの判断基準は必要でしょう。しかし、その基準はもはや「量」の問題ではなくなってきていると私は考えます。
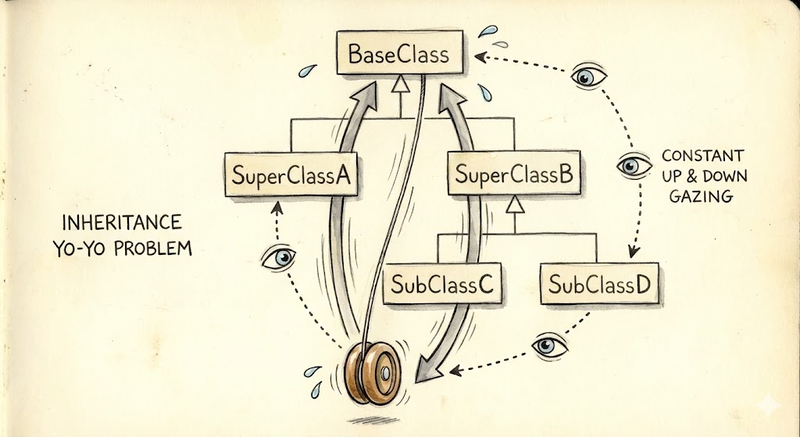
さらに、AIの視点に立ってみましょう。過度に共通化されたコードは、AIにとって「飛び石」のようなものです。 一つの機能を実装するために、あちこちのファイルを参照し、複雑な依存関係を読み解かなければなりません。かつてオブジェクト指向で問題視された「ヨーヨー問題 (継承関係を行ったり来たりする現象)」を彷彿とさせます。AIが回答を生成する際、画面上で猛烈な勢いで複数のファイルを参照して、結局ハルシネーションを含むコードを出力してしまう──そんな光景を、皆さんも目撃したことがあるはずです。
逆に、重複を恐れず作業単位でファイルがまとまっている (Localityが高い) と、AIは迷わず、正確に、そして爆速で実装できます。
真に共通化が必要な部分は、いずれフレームワークやライブラリとして切り出されていくでしょう。今は思い切って、この共通化の美学とでも呼ぶべき感覚を、一度手放してみましょう。
ただし、これには副作用もあります。コードの重複は、人間にとって「認知負荷の増大」を意味します。AIが書いたコードの正当性を人間がチェックする際、似たようなコードが散在していることは混乱の元になり得ます。このアーキテクチャは、「書くコストの削減」と「読むコストの増大」のトレードオフの上に成り立っていることを忘れてはいけません。
勘違いしてほしくないのですが、これは決して「汚いコードを書いていい」と言っているわけではありません。 人間にとっての「読みやすさ (コードの短さやスマートさ)」よりも、AIにとっての「理解しやすさ (文脈の独立性)」を優先するという、新しい価値観への挑戦となります。
スパゲッティは「アルデンテ」のうちに
「重複を許容する」と聞くと、保守不可能なスパゲッティコードが量産される未来を想像してゾッとする方もいるでしょう。 しかし、スパゲッティも茹で加減次第です。 ここで提案しているのは、麺が伸び切ってブヨブヨになった「悪いスパゲッティ」ではありません。芯が残っていて歯ごたえがあり、まだコントロール可能な状態──すなわち「アルデンテ」の状態を維持しながら、爆速で0→1を駆け抜けるための実装戦術です。
プロダクトがPMF(Product Market Fit)を達成し、フェーズが「1→10(安定・拡大期)」に移行した段階で、どのように秩序ある構造(レイヤー化や共通化)へ着地させるか。その「出口戦略」については、記事の後半で詳しく解説します。今はまず「立ち上げの速度」に振り切った世界観にお付き合いください。
直列実装という制約からの解放
もう一つ、私たちがアップデートすべき既成観念があります。それは「実装は一つずつ順番に進めるもの」という直列実装の意識です。
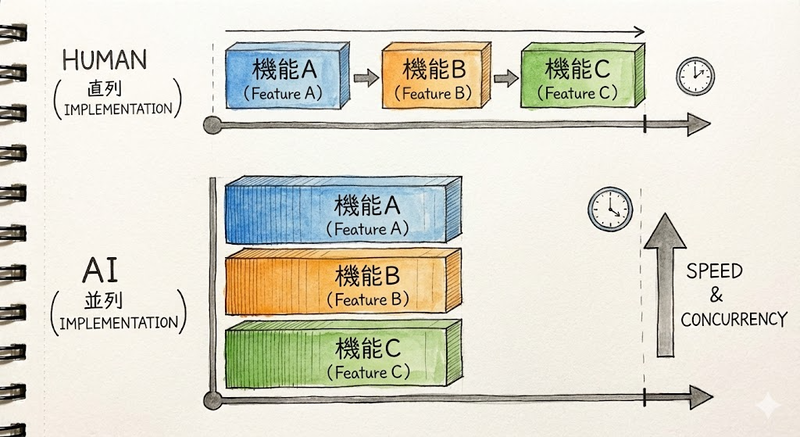
人間がコードを書く場合、マルチタスクは効率を下げます。A機能を作りながらB機能のバグを直し、C機能の設計を考える...そんなことをすれば、脳のコンテキストスイッチがオーバーヒートしてしまいます。だからこそ、私たちはタスクを直列に並べ、一つずつ着実に消化することを良しとしてきました。人間は本質的にシングルタスクなのです。
しかし、AI (AI Coding Agent) にはその制約がありません。 複数のエージェントを同時に立ち上げ、それぞれに異なる機能の実装を任せることができます。 「カート機能」を作るエージェントと、「決済機能」を作るエージェントと、「商品一覧」を作るエージェントが、互いに干渉することなく同時に走り出す。これがAI時代の並列実装です。
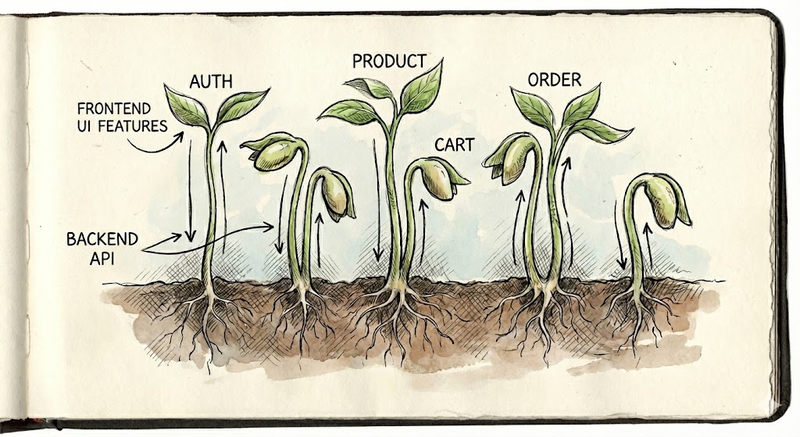
豆苗アーキテクチャ(Bean Sprout Architecture)
この「並列実装」を実現するために必要なのが、先ほど述べた「共通化を捨てる (つまりLocalityを高める)」というアプローチです。 もし、全ての機能が巨大な共通クラスに依存していたらどうなるでしょうか? 複数のエージェントが同時にその共通クラスを編集しようとし、コンフリクトが多発して、開発が止まってしまうでしょう。これでは並列化のメリットを享受できません。
そこで提案したいのが、「豆苗アーキテクチャ(Bean Sprout Architecture)」というイメージです。
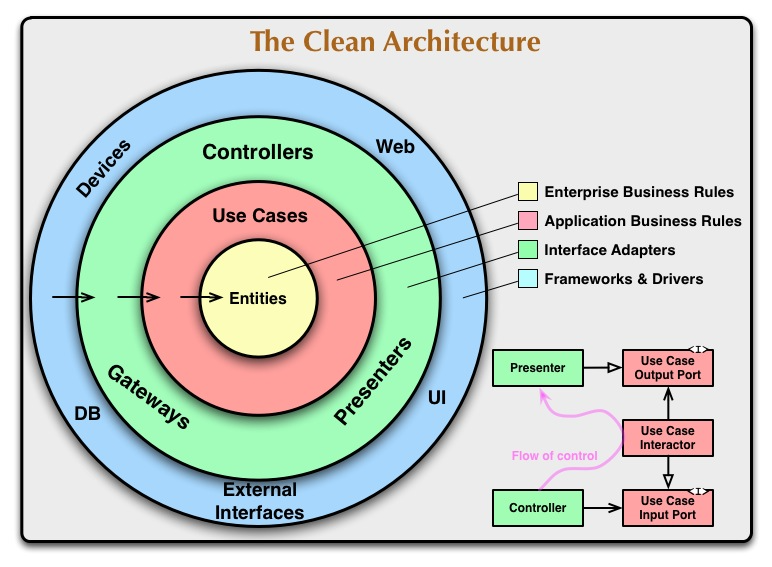
例えば、The Clean Architectureはよく「ドーナツ (同心円)」のイメージで表現されます。中心のドメインを守るために、外側の層が何重にも取り囲んでいます。これは堅牢ですが、一つの機能を実現するために全ての層を貫通しなければならず、関連するコードが物理的に分散してしまう構造です。 対して、今回目指すアーキテクチャのイメージは「豆苗」です。それぞれの苗(作業単位)が苗床や茎(バックエンド)として育ち、太陽に向かって葉(UI)を広げるまで、一気に縦に伸びていきます。隣の苗がどうなっていようと関係ありません。
この「縦に割る (Vertical Slicing)」構造こそが、AI Coding Agentたちが互いの足を引っ張り合うことなく、全力疾走するための専用レーンとなるのです。
ちょっと待って: それは "Package by Feature" では?
勘の鋭い読者であれば、この図を見て「これは結局、議論の尽きない Package by Feature (機能単位のパッケージング) ではないか? 複雑なケースでは依存関係が管理しきれないのでは?」と警戒されるかもしれません。
その懸念は、人間がコードを管理する上ではもっともなものです。 しかし、今回の前提を思い出してください。コードを読み書きする主体は、人間ではなく AI Coding Agent です。
もう少し読み進めていただければ「Package by Feature」 か 「Package by Layer」 かという二元論を超えたアプローチであることがご理解いただけるはずです。
git worktree では解決できないのか?
「ファイルの競合を防ぐだけなら、git worktree などを使ってエージェントごとにブランチを切れば良いのでは?」という疑問を持つ方もいるでしょう。
たしかに、それらの方法は並列エージェントの作業コンフリクトを解消する手法として有効です。
しかし、今回のアプローチの本質は、単なる作業の衝突回避ではありません。 「重複を積極的に許容し、その変更コストをAIエージェントに吸収してもらうことで、それぞれの機能の独立性と変更容易性を担保する」ことにあります。 共通ファイルをブランチで分けて編集しても、マージ時のコンフリクトや、将来的な変更の影響範囲といった「結合のコスト」は残ります。物理的にコードを分けてしまうことこそが、それらを根本から断ち切る解決策なのです。
具体的な実装戦略
では、この「Bean Sprout Architecture」をバックエンドとフロントエンドで具体的にどう実現するのか。 それぞれの領域で具体的な実装戦略を紹介する前に、まずは全体の実装フローを整理します。
思考はUIから、実装はバックエンドから
AI Coding Agentにシステムを作らせる時、最初の指示は何になるでしょうか? それは「どのような画面で、ユーザーは何ができるか」というUI/UXの要件です。データベースのスキーマ設計から入ることは稀でしょう。つまり、私たちの思考は自然と「UI」からスタートします。
しかし、ここで注意すべきは「思考の順序」と「実装の順序」は逆になることが多いという点です。「UIから考える」からといって、必ずしも「フロントエンドのコードから書き始める」のが正解とは限りません。
- 思考 (UI First): どんな画面が必要か?どんなデータが必要か?
- モデリング (Modeling): そのデータをどのような構造体(Schema)で扱うか?
- バックエンド実装 (Backend First): モデルに基づきAPIを実装し、契約(OpenAPI)を出力する。
- フロントエンド実装 (Frontend Second): 出力された契約を使ってフロントエンドを実装する。
バックエンドの実装戦略
Vertical Slice Architecture (VSA)
バックエンドの実装パターンとして、前述の「Bean Sprout Architecture」を具現化するベースアイデアとして Vertical Slice Architecture (VSA) を採用します。 これは、Jimmy Bogard氏によって提唱されたアーキテクチャパターンで、システムを「技術的なレイヤー (Controller, Service, Repository)」で水平に切るのではなく、「機能 (Features)」で垂直に切るというものです。
従来のレイヤーアーキテクチャでは、一つの機能を追加するために複数の層を横断して変更する必要がありました。これは「ドーナツ」の層をすべて貫通するようなもので、影響範囲が見えにくくなります。 一方、VSAでは機能ごとにコードが凝集しているため、ある機能の変更が他の機能に影響を与えることはありません。
AIのための "Locality First"
VSAの思想をさらに推し進め、AI Coding Agentのために「コンテキストの局所性 (Locality)」を極限まで高めます。 具体的には、以下のルールを徹底します。
- 作業単位での分割:
accountという機能ではなくregister_account,get_accountのように、AI Coding Agentの作業単位につき1ディレクトリを作成します。 - 完全な独立性: 各ディレクトリは他のディレクトリを参照せず、DTOやロジックの重複を許容します。
ディレクトリ構造の全体像(Go言語の例)
例えば、アカウントに関するCRUD操作(登録、取得、更新、削除)をGo言語で実装する場合、ディレクトリ構造は以下のようになります。あらゆる種類のファイルが各ディレクトリに存在している点に注目してください。
注: ファイル名などはダミーです。実環境に合わせて設定してください。
cmd/
api/
main.go
internal/
features/
register_account/ // POST /accounts
handler.go // HTTPハンドラ
service.go // ビジネスロジック
repository.go // DBアクセス(モデルの永続化)
model.go // データ構造 (Entity)
list_accounts/ // GET /accounts
handler.go
service.go
repository.go
model.go
get_account/ // GET /accounts/{id}
handler.go
service.go
repository.go
model.go
update_account/ // PUT /accounts/{id}
handler.go
service.go
repository.go
model.go
delete_account/ // DELETE /accounts/{id}
handler.go
service.go
repository.go
model.go
これにより、AIは「このディレクトリだけを見れば完結する」状態になり、迷わず爆速で実装できます。
複雑な業務ロジックの場合は?
「単純なCRUDならそれでいいが、複雑な業務ロジックはどうするのか?」 例えば、ECサイトにおける「注文確定 (place_order)」のような処理です。ここでは「注文の作成」だけでなく、「在庫の引当」「決済の実行」「メール送信」といった複数の責務が絡み合います。
従来のレイヤーアーキテクチャでは、OrderService が InventoryService や PaymentService を呼び出す形になりがちですが、豆苗アーキテクチャでは「そのタスクに必要なすべてをディレクトリ内に集める」アプローチを取ります。
internal/
features/
place_order/ // 注文確定ユースケース
handler.go // POST /orders
service.go // 注文フローの制御(オーケストレーション)
// 必要なリソース操作をここに集める(1対多)
order_repo.go // 注文テーブルへのINSERT
inventory_repo.go // 在庫テーブルのUPDATE (引当)
payment_gateway.go // 決済APIの呼び出し
model.go // このユースケース専用のデータ構造
ここで重要なのは、inventory_repo.go が他の機能(例えば restock_inventory)にある在庫操作ロジックを再利用するのではなく、「注文確定のために必要な在庫操作」として独自に定義される点です。
- 分割の単位: 機能ではなく、作業単位。
- 内部構造: エントリポイント 1つに対し、サービスや外部接続は複数あっても構わない(1対多)。
これにより、AIは「注文確定のロジックを変えたい」と言われた時、place_order ディレクトリの中だけを見れば、在庫引当のロジックも含めてすべてを把握し、修正することができます。
もちろん、別のディレクトリでも似たような実装が出てくるでしょう。ですが0->1実装の段階においてこの重複は許容します。
分割の粒度は「AIのコンテキストウィンドウ」に合わせる
本記事では、最も極端に独立性の高い「ユースケース単位(Create/Read/Update/Deleteを別ディレクトリにする)」の構成を作業単位と見立てて例示しました。 しかし、AI Coding Agentの進化によっては「CRUDをひとまとまりにする(リソース単位)」方が効率的な場合も十分にあり得ると考えています。
例えば、account というディレクトリの中に、登録・更新・削除のロジックを同居させるパターンです。
internal/
features/
account/ // アカウント管理(CRUDをまとめる)
handler.go
service.go
model.go
もちろん集約のような複雑な単位は別のアプローチをとって段階的に組み上げる必要もあるかもしれません。あるいは、登録/更新/削除(コマンド)と参照(クエリ)で作業単位のディレクトリを分割するのも一つの選択かもしれません。
判断の基準は「AIが一度に理解できるコンテキスト量」です。 まとめて作業したほうがAIが正確に実装できるなら、まとめてしまうのがこのアプローチの本質です。 「必ず1エンドポイント1ディレクトリ」という教条主義に陥る必要はありません。「AIにとってのLocality(関連するものが近くにあるか)」さえ満たされていれば、その粒度は柔軟に調整可能です。
「単純なCRUDでそこまでやるのか? 管理しきれないのでは?」 その直感は、人間がコードを書く上では正しいです。しかし、これは「AIエージェントが互いに干渉せず、並列でコードを生成するためのフォーメーション」です。
まずは散らかしてでも作り切り、後から整える。この順序の違いが、AI時代の開発スピードを決定づけます。(※繰り返しますが、共通化やリファクタリングの出口戦略については後述します。)
実践例(Go言語の場合)
先述した通り、バックエンドの実装の前にここではUI/UX要件は決まっているものとします。次の手順としてはモデリングになります。しかし、その前に実装を円滑に進めるためのおまじないを準備しましょう。
カスタムコンテキストファイルで実装に一貫性を持たせる
コードの重複を許容する本アーキテクチャにおいて、実装の品質と一貫性を担保する唯一にして絶対の指針となるのが、このAI Coding Agentに対するInstructions (指示書) です。
GitHub CopilotなどのAIツールには、プロジェクト固有のルールを教えるための仕組み (.github/instructions/*.instruction.md や .cursor/rules/*.mdc など) が存在します。
- 注: GitHub CopilotはInstructionsを暗黙的に参照した上で実装してくれます。
- 注: Instructionの記載例は簡易的なものです。実際にはプロジェクトに合わせて具体的かつ効果的なInstructionを書いてください。
実装ガイドライン
なるべくプロンプトがシンプルになるように汎用的な内容を記載しておきます。
- 対象のディレクトリ以外の部分をインポートして利用してはいけません。 - 各ファイル毎の実装方法は実装テンプレートを参照してそれに倣った実装を行なってください。 - 必ずユニットテストをセットで実装して、そのテストの通過ももってタスクの完了としてください。
実装テンプレート
ファイルごとの「実装テンプレート」を明記しておくことも大切です。
例えば .github/instructions/handler.instruction.md に以下のようなルールを記述しておきます。
handler.instruction.md
# HTTP Handler実装ルール - リクエストボディのバリデーションを行うこと - Service層のメソッドを呼び出すこと - エラーハンドリングを行い、適切なHTTPステータスコードを返すこと ## 実装テンプレート func (h *Handler) Handle(w http.ResponseWriter, r *http.Request) { ... }
この「秩序」を事前に定義しておけば、AIへのプロンプトは以下の短い一言で済みます。
「register_account 機能を実装してください。」
これだけで、AIは定義されたテンプレートに従い、迷うことなく、他の機能を壊す心配もなく、爆速で整然としたコードを生成してくれます。
さらに、テストコードも同時に生成されるため、実装と同時に品質も担保されます。 コードが重複しているということは、テストもそれぞれの機能専用に独立して存在しているということです。これこそが「変更容易性」を保証します。
Tips: 仕様書をコンテキストとして配置する
Instructionsはあくまで「書き方のルール (How)」です。「何を作るか (What)」を伝えるために、spec.mdを配置するのも有効です。
ただし、ここで言う「仕様書」とは、従来の開発のような重厚なドキュメントではありません。あくまで「AIに適切なロジックを組み立ててもらうための指針」としてのメモ書きのようなもので構わないと思います。人に読んでもらうというよりAIに読んでもらうためのものなので簡潔に論理的な箇条書きで良いです。
spec.md の例
# アカウント登録のビジネスルール - ユーザー名は3文字以上20文字以下 - パスワードは8文字以上、英数字記号を含むこと - 既に存在するメールアドレスの場合はエラーを返す
開発単位 (Feature) の中で、これから実装するロジックの要点を箇条書きにする。それをAIに読み込ませることで、バリデーションやエッジケースの実装漏れを防ぐことができます。
モデリング
Instructionsで「書き方」のルールを定めたら、次は「データの形」を決めます。
従来の手順では、register_account を作り、その後に get_accounts を作る……というように、機能実装の中でデータ構造も徐々に固まっていくのが一般的でした。
しかし、AIエージェントを並列で走らせる場合、このやり方では問題が起きます。エージェントごとに「UserID なのか AccountID なのか」といった命名の揺らぎ(方言)が生じたり、Accountというモデルが持つプロパティがそれぞれで揃っていないと、データベースなどに保存する際に整合性が取れません。
そのため、実装指示を出す前に、扱うデータの構造(スキーマ)だけは確定させておきます。
重要:データベースのスキーマ(DDL)は「苗床(共通基盤)」として最初に定義します。
各エージェントが勝手にテーブル定義を変更することは許されません。ここで作成する model.go は、あくまでその共通のテーブル定義に対する「各機能専用のアクセサー(構造体)」としての役割を持ちます。
ここで最も重要なポイントは、「モデルを定義するが、物理的には共通化しない」ということです。
先ほどのディレクトリ例にあったように、各ディレクトリに model.go を配置し、あえて同じ構造体をそれぞれの場所に定義させます。
なぜなら、共通の model.go を作ってしまうと、それが「作業コンフリクトの温床」になるからです。
複数のエージェントが同時に一つのファイルを編集しようとすれば、必ず競合が発生します。
「中身は同じでも、物理的に別のファイルとして定義する」。これにより、各エージェントは他者の干渉を一切気にすることなく、自分の担当するディレクトリの中だけで作業を完結させることができます。
ここでも「まずは垂直に作り切る」という原則を徹底します。(※繰り返しますが、共通化やリファクタリングの出口戦略については後述します)
AI Coding Agentによる並列実装のシミュレーション
モデリングを行いました。残りの実装として5つのエージェントを同時に立ち上げ、それぞれに指示を出してみましょう。
事前に Instructions で「書き方 (How)」を、model.go やspec.mdで「扱うデータ (What)」を定義しているため、プロンプトはこれほどシンプルで済みます。
- エージェントA「
register_account機能を実装してください。」 - エージェントB「
list_accounts機能を実装してください。」 - エージェントC「
get_account機能を実装してください。」 - エージェントD「
update_account機能を実装してください。」 - エージェントE「
delete_account機能を実装してください。」
互いの作業領域(ディレクトリ)が物理的に分かれているため、コンフリクトは起きません。瞬く間に豆苗が育つかのごとく、5つのエンドポイントが同時に完成するでしょう。
契約の出力:OpenAPI
バックエンドの実装が完了したら、その成果物をフロントエンドへ引き渡すための「契約書」を作成します。すなわち、OpenAPI (Swagger) 定義の出力です。
もちろん、ここもAIエージェントで実装されたコード(ハンドラや構造体)を読み込ませ、「このコードからOpenAPI定義(YAML)を生成して」とお願いします。あるいはInstructionsに組み込んでしまっても良いかもしれませんね。
この定義ファイルが、後述するフロントエンド実装に対する契約となります。ドキュメントを手書きする必要はありません。「実装から契約を生成し、それを次のエージェントへと渡す」というリレーが行われます。
実装フローのまとめ
- Instructionsの整備: AIへの指示書(テンプレート)を事前に用意する。
- モデリング: 各作業単位ディレクトリに
model.goを配置し、データ構造を定義する(共通化しない)。 - 並列実装: 複数のエージェントに各エンドポイントの実装を指示する。
- 契約の出力: 実装からOpenAPI定義を生成し、フロントエンドへ渡す。
フロントエンド(モバイル・Web)の実装戦略
注: 本記事では、iOS/AndroidアプリやWebフロントエンドなど、ユーザーインターフェース (UI) を構築・操作するクライアントサイドを総称して「フロントエンド」と呼びます。
Feature Sliced Design (FSD)
フロントエンドの実装パターンとして、Feature Sliced Design (FSD) の思想を取り入れます。 これは、特定の個人が提唱したものではなく、大規模なフロントエンド開発における課題を解決するために、コミュニティ主導で議論・体系化されてきたアーキテクチャ設計論です(2018年頃から議論が始まり、現在も進化を続けています)。
Jimmy Bogard氏のVSAがバックエンドの垂直分割を目指したのと同様に、FSDはフロントエンドにおいて、UIを「技術的な役割 (Components, Hooks, Utils)」ではなく「ビジネス価値 (Features)」で分割することを提唱しています。
従来のフロントエンド開発では、再利用性を高めるために「共通コンポーネント」を早期に作りがちでした。しかし、これはバックエンドの「共通化の美学」と同様、AIにとってはコンテキストの分散を招く要因となります。 そこで本記事では、FSDの厳格なレイヤールールをそのまま適用するのではなく、AIエージェントにとっての「理解しやすさ」を最優先にカスタマイズした構成を採用します。
AIのための "Locality First"
バックエンド同様、フロントエンドでも「コンテキストの局所性 (Locality)」を最優先します。 AIが画面を実装する際、必要な情報が作業単位のディレクトリ内に完結していることが重要です。
- 作業単位の凝集: 例えば
features/sign_in/ディレクトリの中に、UIコンポーネント、状態管理(Hooks)、スタイル、API通信ロジックの全てを配置します。 - 早すぎるDRYを避ける: ボタンや入力フォームといった基本的なUIであっても、安易に
shared/componentsに共通化しません。sign_in/SignInButton.tsxとregister/RegisterButton.tsxが重複していても、まずはそれぞれのディレクトリ内に閉じて実装することを許容します。 - コロケーション (Colocation): コンポーネントファイルのすぐ隣に、関連するスタイル、テスト、ストーリーブックを配置します。
これにより、AIは「このディレクトリを見れば、画面の見た目から裏側のロジックまで全てがわかる」状態になります。
Atomic Designのように、一つの機能を修正するために Atoms, Molecules, Pages といった階層を行き来する必要がなくなり、AIのコンテキスト効率が最大化されます。
ただし、デザインシステム (Theme) やグローバルな状態管理など、アプリケーション全体で積極的に統一すべき内容については例外です。これらをどう扱うかについては、後述します。
実装例(Flutter/Dart)
FSDの概念に基づき、作業単位を軸にディレクトリを構成します。
従来のレイヤー構造や、共通化のための shared, util, helperといったディレクトリは廃止し、作業ディレクトリ直下にフラットに配置します。
注: ファイル名などはダミーです。実環境に合わせて設定してください。
lib/
main.dart
pages/ // 画面単位の構成(ルーティングとFeaturesの結合)
sign_in_page/
sign_in_page.dart
features/
email_sign_in/ // メールサインイン機能
email_sign_in_form.dart
email_sign_in_provider.dart // 状態管理とロジック
email_sign_in_service.dart // API通信
email_sign_in_state.dart // この機能専用のデータ型
social_sign_in/ // ソーシャルサインイン機能
social_sign_in_buttons.dart
social_sign_in_provider.dart
view_account_avatar/ // ユーザーアバター表示機能
account_avatar_view.dart
account_avatar_state.dart
view_product_list/ // 商品一覧表示機能
product_list_view.dart
product_list_provider.dart
product_list_service.dart
product_list_state.dart
manage_cart/ // カート管理機能
cart_view.dart // カート画面
add_to_cart_button.dart // カート追加ボタン
cart_provider.dart
cart_service.dart
補足:画面の凝集度と分割粒度
バックエンド同様、フロントエンドにおいても「必ず1機能1ディレクトリ」に固執する必要はありません。 特に、画面遷移やデータ共有が密接な画面群は、一つのディレクトリとしてまとめることが有効です。
例えば、「商品一覧 (List)」と「商品詳細 (Detail)」は、ユーザー体験としてもデータ構造としても一連の流れにあります。これらを view_products という一つのディレクトリにまとめ、product_list.dart と product_box.dart を同居させることは理にかなっています。
AIに指示を出す際も、「商品一覧と詳細を作って」とセットで依頼することで、一覧から詳細への遷移ロジックや、引数の受け渡し(Navigation Arguments)の整合性が取りやすくなります。
このように、account という大きなリソース単位でディレクトリを切るのではなく、「メールサインイン (email_sign_in)」「ソーシャルサインイン (social_sign_in)」といった、よりAI Coding Agentの作業単位で分割します。余談ですがFSDを参考にしている手前、「feature」という単語を使ってしまっている箇所があるかもしれませんが、この記事では機能にはこだわっていません。用語が重複しますが、本記事の文脈においては「機能」というよりも「作業単位」としてご理解ください。つまり「作業単位」が「機能」に一致するケースはありますが、必ずしも「機能」が「作業単位」に一致するわけではありません。
さらに、ファイル名にも機能名や具体的な役割を含めることを推奨します(例: form.dart ではなく email_sign_in_form.dart)。これにより、AIがファイルの中身だけを見た際にも「どの機能に属するファイルか」を即座に理解でき、ハルシネーションのリスクを低減できます。
これにより、AIは「features/email_sign_in を実装して」と指示されるだけで、そのディレクトリ内に必要なUI、状態管理(Provider)、API通信(Service)を全て生成し、完結させることができます。他のディレクトリ(utils や shared)を探しに行く必要はありません。
カスタムコンテキストファイルで実装に一貫性を持たせる
バックエンド同様、フロントエンドでもInstructionsが威力を発揮します。 特にUIフレームワークは「書き方の自由度」が高いため、AIに明確なレールを敷くことが重要です。
.github/instructions/*.instruction.md の活用イメージ
画面 (Page) だけでなく、ボタンやダイアログといったコンポーネント単位で細かいルールを定義します。
button.instruction.md
# Button実装ルール - 内部状態管理はHooksで完結させること - グローバル状態管理やデータプロバイダーが必要な場合はRiverpodを利用すること - スタイリングにはデザインテーマを利用すること ## 実装テンプレート class Button extends HookWidget { ... }
このように dialog, card など、役割ごとにきめ細かく指示書を用意することで、AIはデザインシステムに準拠したUIを正確に量産できるようになります。
契約の入力:OpenAPI
フロントエンド実装において、バックエンドとの整合性を担保する重要な要素が、OpenAPIという契約 です。 これにより、エンドポイントのパス間違いや、フィールド名のズレ (camelCase vs snake_caseなど) といった、人間が犯しやすいミスをゼロにできます。 バックエンドの実装がOpenAPIを経由して、そのままフロントエンドのコードへと変換される。これにより開発スピードと品質を両立させます。ここは従来の実装においても相違ない箇所かと思います。
AI Coding Agentによる並列実装のシミュレーション
ここでも並列実装が可能です。バックエンドと同様に、5つのエージェントを同時に走らせることができます。
- エージェントA「メールサインイン機能を実装してください。」
- エージェントB「商品一覧機能を実装してください。」
- エージェントC「商品詳細機能を実装してください。」
- エージェントD「カート管理機能を実装してください。」
- エージェントE「注文機能を実装してください。」
互いのディレクトリは独立しているため、コンフリクトは発生しません。
ページの組み立て
最後に、それぞれのパーツを使って最終的なページを組み上げます。 ここはAIに任せても良いですが、人間がパズルのピースをはめるように Page コンポーネントを実装し、ルーティング定義に追加する方が、全体の構成を把握する上では良いステップになるかもしれません。
実装フローのまとめ
- Instructionsの整備: UIコンポーネントや状態管理の実装ルールを事前に用意する。
- 契約の受領: バックエンドからOpenAPI定義を受け取る。
- 並列実装: 複数のエージェントに各作業単位 の実装を指示する。
- 結合: 実装された作業単位 を組み合わせてページ (Page) を作成し、ルーティングに登録する。
Webフロントエンド特有の考慮事項
本記事では主にモバイルアプリやSPA (Single Page Application) を念頭に置いた構成を紹介しましたが、Webフロントエンド (特にNext.jsなどのモダンフレームワーク) においては、さらに考慮すべき重要な要素があります。
それは「ブラウザへのデリバリーとレンダリング戦略」です。
Webフロントエンドは、単にUIを構築するだけでなく、いかに高速にユーザーにコンテンツを届けるか (Core Web Vitals) がビジネス価値に直結します。そのため、SSR (Server-Side Rendering)、CSR (Client-Side Rendering)、ISR (Incremental Static Regeneration)、そしてHydrationといったレンダリングの制御が不可欠です。
今回提案した「Locality First」なアプローチ(機能ごとの垂直分割)が、これらの高度なレンダリング最適化やバンドルサイズにどのような影響を与えるかについては、まだ明確な解を持ち合わせていません。 例えば、コードの重複を許容することでバンドルサイズが増大し、初期ロード時間が遅延するリスクも考えられます。あるいは、Next.jsのApp Routerのように、ディレクトリ構造自体がルーティングやレンダリング境界と密接に関わるフレームワークとの整合性をどう取るかも課題です。
AI時代のアーキテクチャは、開発効率 (Developer Experience) とユーザー体験 (User Experience) のバランスをどう取るか、という新たな課題に、私たちは向き合わなければなりません。この点については、今後の探求領域として記しておくにとどめます。
共通化をインフラとして再定義する
ここまで「共通化を捨てよ」と説いてきましたが、ここで改めてこの言葉の真意を補足します。 AI時代において、共通化は完全に不要になるわけではありません。ただし、その目的は「コード量の削減 (抽象化)」から「システムの足回りの統一 (インフラ化)」へと変化します。
これは、開発フェーズに応じた戦略の使い分けでもあります。
- 0→1 (立ち上げ期): 垂直 (Vertical) に走る。 重複を恐れず、スピードと独立性を最優先する。
- 1→10 (安定・拡大期): 水平 (Horizontal) に整える。 安定した部分を見極め、慎重にインフラ化する。
多くのプロジェクトが停滞するのは、0→1の段階で早すぎる水平化(共通化)を行ってしまうからです。 その共通化は、「責務が一緒のように見える」「コードシグネチャが一緒だ」「将来使い回せそうだ」といった、確定していない未来に対する曖昧な予想に基づいて行われます。 まずは垂直に作り切り、後から慎重に共通化する。この順序こそが肝要です。
リファクタリングの判断基準
垂直に機能を実装した後、改めて全体を見渡すと、たくさんの重複しているコードが見えてきます。 ここで、何も考えず次々と「重複を排除 (抽象化)」するのではなく、 まずは「システム基盤として切り出す (インフラ化)」べきか否かを選別します。
判断基準はシンプルです。 「そのコードは、共通化によって意図しない副作用 (デグレ) を生む恐れがあるか?」
- Yes: 共通化してはいけません。 特定の機能のための修正が、他の機能へ波及してしまうリスクを避けるためです。AIにとって、機能間の独立性は修正の容易さに直結します。
- No: 共通化すべきです。 例えばログの形式や認証の仕組みなど、システム全体で統一されるべき振る舞いです。これらは機能ごとの都合で変更されるべきではありません。
コラム:消費税率が変わったら10箇所も修正するのか?
「共通化しない」と聞くと、多くのエンジニアは「消費税率のようなビジネスロジックが変わった時、全箇所を修正して回るのか?」と不安になるでしょう。 結論から言えば、小規模な重複はテストで安全性を担保し、大規模で複雑なロジックは「共通基盤」として切り出します。
「共通化による一貫性担保」から「テストによる振る舞いの担保」へと比重がシフトします。各作業単位ディレクトリには、AIが生成した「そのロジックが正しく動くことを保証するテスト」が必ずセットで存在します。もし修正漏れがあれば、CIでテストが落ちるだけです。
もちろん、それでも管理しきれないほど複雑・大規模なロジックであれば、そこは迷わず「苗床 (共通基盤)」とみなして共通化すべきです。大切なのは「絶対に共通化してはいけない」と意固地になることではなく、密結合とのトレードオフを意識し、運命共同体になってでも避けるべき重複であれば共通化するという、従来通りの判断を行うことです。
バックエンドにおける共通化
共通化すべきもの(コードとしてのインフラ)
これらは「アプリケーションの土台」であり、システム全体で厳密な一貫性が求められる部分です。
- 認証・認可基盤: ユーザーの特定や権限チェックの仕組み。
- ロギング・監視: ログフォーマットやメトリクス送信の仕組み。
- 環境変数・シークレット管理: 設定値の読み込みや管理方法。
- 外部システム接続(DB/HTTP)の初期設定: コネクションプールやタイムアウト設定などのポリシー。
これらを共通化することは「密結合」を生みますが、これらは「運命共同体 (変更時は全機能が一斉に追従すべき)」であるため問題ありません。 前述の「Bean Sprout Architecture」で例えるなら、これらは個々の苗 (機能) が育つための「苗床 (共通基盤)」にあたります。 AIエージェントには「この苗床 (共通基盤) の上で実装して」と指示することで、個別の実装品質を底上げできます。
共通化すべきでないもの(ヘルパー/ユーティリティなど)
一方で、以下のような「機能ごとの都合で変わりうるもの」や「ちょっとした共通実装」は共通化の対象外です。
- 汎用的なバリデーションロジック: 「メールアドレスの形式チェック」程度であれば、各機能にコピーされていても構いません。共通ライブラリへの依存は、微細な仕様変更の足枷になります。
- DTO変換やデータ加工:
UserオブジェクトをAPIレスポンスに変換する処理などは、機能ごとに微妙な差異(フィールドの有無など)が発生しやすいため、あえて重複させます。 - 継承を前提としたBaseクラス:
BaseControllerのような親クラスは、AIにとってコンテキストの分断(ファイルを行き来するコスト)を生む最大の敵です。
実装の重複コストはAIが吸収します。コードスタイルの統一は、共通クラスや継承ではなく「Instructions (テンプレート)」によって担保します。
フロントエンドにおける共通化
フロントエンドも基本方針は同じですが、UIコンポーネントという視覚的な要素があるため、少しアプローチが異なります。
共通化すべきもの(デザインシステム・グローバル状態管理)
これらはアプリケーションの「見た目と振る舞いのルール」であり、厳格に統一されるべき部分です。
- デザインシステム (Theme / Tokens): 色、フォント、スペーシングなどの「定義値」。ここがズレるとデザインが毀損します。
- グローバル状態管理: ユーザーセッションやトースト通知など、アプリ全体で共有される状態。
- APIクライアント基盤: リクエストヘッダーの付与(Auth Token)や、共通のエラーハンドリング。
- ルーティング設定: ページ遷移のルールやガード処理。
共通化すべきでないもの?(UIコンポーネント)
ここが最も判断に迷う部分でしょう。「ボタンやカードなどの汎用コンポーネントは共通化すべきでは?」と。 結論から言えば、「Humble Object(振る舞いを持たない純粋なView)」か否かで判断します。 Humble Object(控えめなオブジェクト)とは、元来テストが困難なGUI描画部分からロジックを排除するためのパターンです。この「ロジックを持たず、渡された値を表示するだけ」という特性こそが、AI時代における安全な共通化の境界線となります。
UIプリミティブ / Humble Components (共通化OK):
Button,Card,Input、あるいはそれらを組み合わせたIconWithTextのようなコンポーネントです。 これらはPropsを受け取って表示するだけの「純粋な見た目(View)」であり、内部に複雑なロジックやAPI通信を持ちません。これらはデザインシステムの一部(コードとしてのインフラ)として積極的に共通化すべきです。Smart Components / Connected Components (共通化NG):
UserSearchFormやPaymentButtonのような、特定のユースケースに特化したコンポーネントです。 これらは内部に「APIを叩く」「バリデーションを行う」といった「振る舞い(Behavior)」を含んでいます。これらを「似ているから」といってSharedFormのように共通化するのはアンチパターンです。
「共通化されたHumbleなパーツを使い、その場でSmartなコンポーネント (機能) を組み立てる」アプローチが良いのではないでしょうか。
もし、似たような SignInButton が複数の画面で重複してしまったら?
0→1フェーズでは、それを許容します。
無理に共通化して「あちらを立てればこちらが立たず」の調整コストを払うより、コピーして独立性を保つ方が、AIによる並列実装(作業単位の分割)を阻害しないからです。
0→1 から 1→10 へ:フェーズによる変化
ここまで、作業単位毎にディレクトリを切ったり、重複モデルをあえて設置したりと、従来の常識からすると懐疑的に思える手法を提案してきました。「後述します」として保留にしてきたこれらの点について、ここで回答します。
これまでの話は、あくまで0→1フェーズ(立ち上げ期)において、AI Coding Agentを並列稼働させ、作業コンフリクトを発生させず、爆速で実装を実現することに焦点を当てたものです。 しかし、1→10フェーズ(安定・拡大期)に入り、長期的な保守運用を行っていくにあたっては、事情が異なってきます。
アーキテクチャに銀の弾丸はない
判断の基準は一概には決められません。これはAIの文脈に限らず、従来の開発でも同様です。 プロダクトにフィットするアーキテクチャは、開発フェーズ、規模感、内製か受託か、チームの技術力、そしてビジネスドメイン(例:金融のような高いセキュリティや厳密なデータ整合性が求められる領域か)といった様々なパラメータによって変化します。
極端な話、0→1で作りきったバーティカルな構造(豆苗アーキテクチャ)を、フェーズが変わった段階でClean Architectureのようなレイヤー構造へリファクタリングするのも、有力な選択肢の一つです。 すでに機能は動いており、テストコードも担保されています。AI Coding Agentの圧倒的な実装スピードがあれば、大規模なリファクタリングも以前ほど恐ろしいコストではありません。AI Coding Agentを利用したこの水平化の試みを考えてみるのも面白そうですね。
この点において、豆苗アーキテクチャは教条的な "Package by Feature" とは異なります。そもそもfeatureでもなく作業単位であることはわかっていただけたと思います。いつ、何を「苗床(共通基盤)」として切り出すかは、チームが自律的に決定できます。
AI時代のレイヤリングの指針
ただし、AI Coding Agentと共に開発を続けるのであれば、いくつか意識してほしい点があります。 それは、漫然とレイヤリングを行うのではなく、「機能追加や改修時に、AIが迷わない構造か?」を常に問い続けることです。
前述の問いを思い出してください。 「そのコードは、共通化によって意図しない副作用 (デグレ) を生む恐れがあるか?」
「共通化」は常に「密結合」とのトレードオフです。 1→10フェーズで共通化を進めるということは、そのコードを「運命共同体」にするという覚悟を決めることです。 「ここを直したら、あそこも一緒に変わってほしい」のか、「変わってほしくない」のか。その影響範囲を見極めることが何より重要だと私は考えています。
個人的に推奨するアプローチは、マイクロサービス移行の文脈で語られた「ストラングラーパターン(絞め殺しパターン)」の応用です。 最初から完璧なレイヤー構造を目指すと、AIにとってのLocalityを見誤る可能性があります。まずは垂直に作り、機能追加や改修の「痛み(重複の辛さ)」を実感した箇所から、必要に応じて段階的にレイヤリング(共通化)していくのが良いのではないでしょうか。
共通コードのインターフェース設計
また、共通化したコードのインターフェース(シグネチャ)にも配慮が必要です。
関数やメソッドの引数は、AIが直感的に理解できるものになっていますか?
default 値や null 許容によって挙動が複雑に分岐する場合、AIは誤った使い方をするリスクが高まります。そのような場合は、用途ごとに別名のメソッドでラップすることを検討してください。
また、コード内コメント(DocString)には、人間向けだけでなく、AI向けに「どのような文脈で使うべきか」を明記しましょう。そうすることで、共通コードであってもAIが適切に利用できるようになります。
これまでの違和感や抵抗感は、少し解消されましたでしょうか? フェーズに合わせて柔軟に形を変えていく。それもまた、植物(豆苗)のようなしなやかさを持つこのアーキテクチャの特徴なのです。
まとめ
本記事では、AIという新たな「開発パートナー」を迎えた今、従来のソフトウェアアーキテクチャに対する捉え方をゼロベースで見直すことによる可能性を説いてきました。
これらの一連の提案は、AI時代のソフトウェアアーキテクチャが、人間にとっての「読みやすさ (DRY)」から、AIにとっての「扱いやすさ (Locality)」へとその軸足を移しつつあることを示唆していると言えるのではないでしょうか。
- Locality First: 共通化への執着を捨て、実装単位ごとに垂直に切り出す。
- Parallel Implementation: 直列作業を捨て、複数のエージェントを同時に走らせる。
- Infrastructure as Common: 安易な抽象化を捨て、システム基盤としての共通化に徹する。
「二度書くな (DRY)」という戒律から、そろそろ解き放たれましょう。 恐れずに繰り返すのです。どうせ書くのは、もはや私たちではないのですから。
おわりに:これは一つの「思考実験」です
ここまで、あえて既存の常識に挑むような強い言葉を使ってきましたが、本記事は先人たちが築き上げた素晴らしいアーキテクチャを否定するものではありません。 むしろ、それらを学んできた一人のソフトウェアエンジニアとして、「もしAIが主役の世界がこのまま突き進むなら、アーキテクチャはどう進化するのか?」という問いに対する、現時点での思考実験です。
ここで提唱した手法が絶対的に有効だとは思いません。実際に運用してみれば、想定外の落とし穴も見つかるでしょう。半年後には私自身が「やっぱりあのアイデアは極端すぎた」と苦笑している可能性だってあります。
ただ、この「未完成のアイデア」が、皆さんの開発チームにおける議論の種(あるいは酒の肴)になれば幸いです。 「それは極端すぎる」と笑い飛ばすもよし、「部分的に取り入れてみるか」と実験してみるもよし。 もし何か面白い発見があれば、ぜひ教えてください。ソフトウェアアーキテクチャ談義を楽しみにしています。
参考文献・インスパイアされた概念
本記事の執筆にあたり、以下の既存概念や思想から多くの影響を受けています。 AI時代の文脈に合わせて勝手な再解釈をしていますが、その源流は偉大な先人たちの知恵にあります。
- Locality of Behaviour (LoB): htmx作者Carson Gross氏が提唱。「振る舞いの定義は近くにあるべき」という思想は、本記事の「Locality First」の基礎となっています。
- Screaming Architecture: Clean Architecture著者Robert C. Martin氏が提唱。「ディレクトリ構造はシステムが何をするかを叫ぶべきだ」という考えです。
- Modular Monolith: マイクロサービスとモノリスの中間解。機能ごとの境界を明確にするアプローチは、VSAの構造と強く共鳴します。
- Go Proverbs: "A little copying is better than a little dependency."(少しのコピーは少しの依存に勝る)。Rob Pike氏のこの格言には大変感銘を受けたことを覚えています。
- Vertical Slice Architecture (VSA): Jimmy Bogard氏が提唱。レイヤーではなく機能で垂直に切るアーキテクチャ。本記事のバックエンド実装の核となる概念です。
- Feature-Sliced Design (FSD): フロントエンドにおける機能分割の設計思想。本記事のフロントエンド実装のベースとなっています。
その他の参考文献/出典
- Structured Design (1979) - Edward Yourdon, Larry L. Constantine
- A Pattern Language (1977) - Christopher Alexander
- Domain-Driven Design (2003) - Eric Evans
- Clean Architecture (2012) - Robert C. Martin
- Atomic Design (2013) - Brad Frost
